JavaScript引擎也是一个应用程序,是JavaScript的执行环境,是浏览器的组成部分,每个浏览器对应的JavaScript引擎不同,chrome是v8,firefox是SpiderMonkey,safari是Nitro
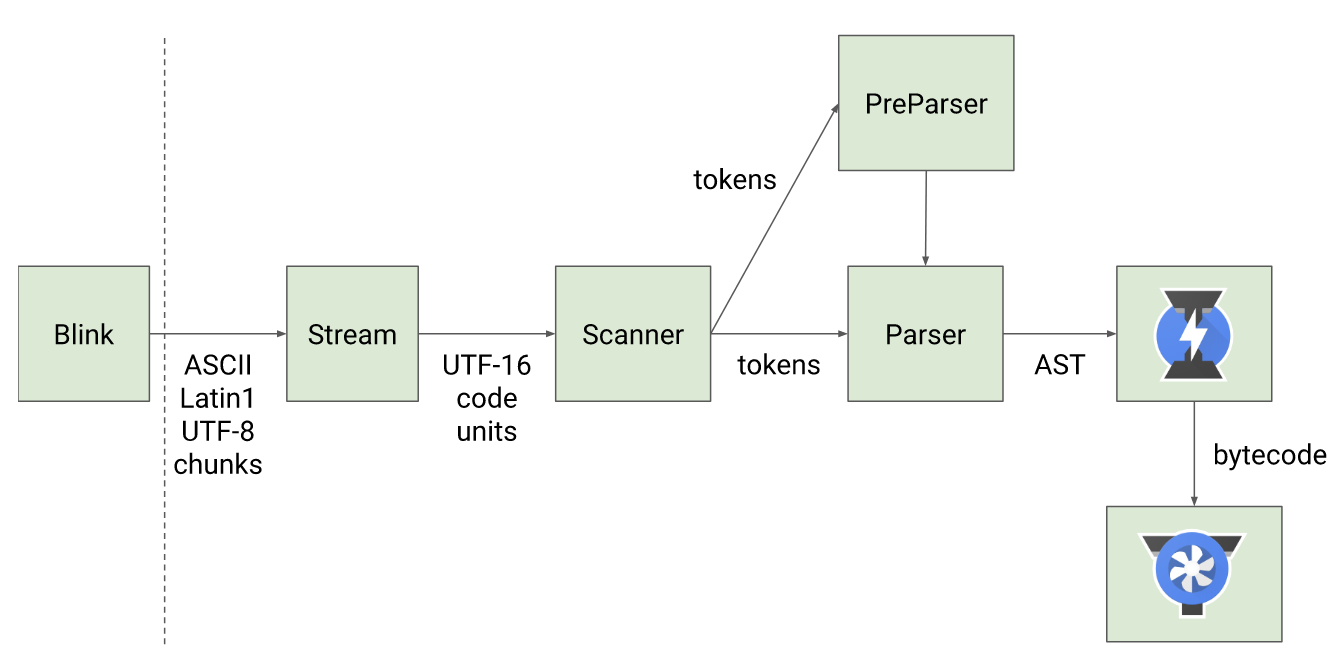
Blink 是谷歌浏览器的渲染引擎,V8 是 Blink 的内置 JavaScript 引擎
Scanner
scanner 是一个扫描器,用于对纯文本的 JavaScript 代码进行词法分析。它会将代码分析为 token
token:是指语法上不能再分割的最小单位,可能是单个字符,也可能是一个字符串
const a = 20
[
{
"type": "Keyword",
"value": "const"
},
{
"type": "Identifier",
"value": "a"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "Numeric",
"value": "20"
}
]
代码对应token集合
Parser
parser 模块可以理解为是一个解析器。解析过程是一个语法分析的过程,它会将词法分析结果 tokens 转换为抽象语法树「Abstract Syntax Tree」,同时会验证语法,如果有错误就抛出语法错误。
parser 的解析有两种情况,预解析与全量解析
JavaScript代码转为AST - esprima
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "a"
},
"init": {
"type": "Literal",
"value": 20,
"raw": "20"
}
}
],
"kind": "const"
}
],
"sourceType": "script"
}
代码对应抽象语法树
预解析 pre-parsing: Layze
代码中有大量未被使用的部分,若全都进行Full-parsing ,解析过程会浪费许多实际,做无用功
预解析的方案,它在提高代码执行效率上起到了非常关键的作用。它有如下特点
-
预解析会跳过未被使用的代码
-
不会生成 AST,会产生不带有变量引用和声明的 scopes 信息
-
解析速度快
-
根据规范抛出特定的错误
function foo1() {
console.log('foo1')
}
function foo2() {
console.log('foo2')
}
foo2();
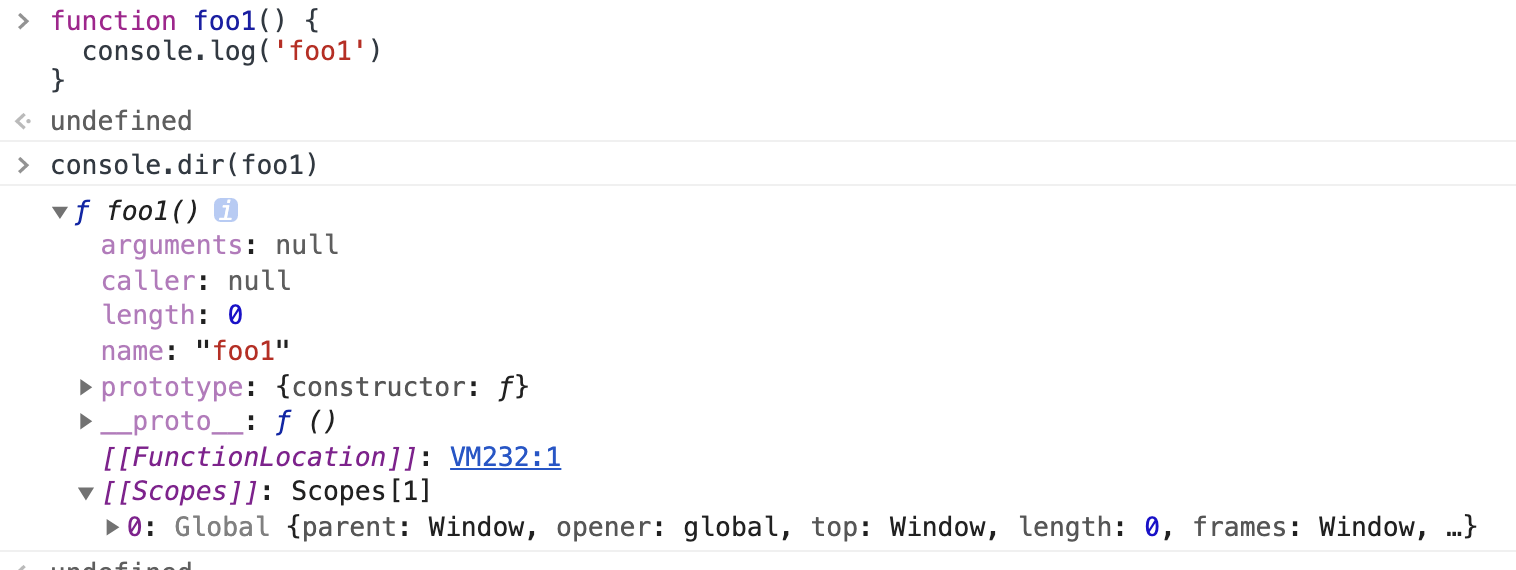
只有foo2被执行,foo1就是被预解析,但会生成作用域链 [[scope]]
全量解析 Full-parsing: Eage
检测到代码会被执行或立即执行时,会生成AST,即全量解析
- 解析被使用的代码
- 生成 AST
- 构建具体的 scopes 信息,变量的引用,声明等
- 抛出所有的语法错误
全量解析后会创建执行上下文(定义变量/方法) 作用域与作用域链的信息是在预解析阶段就已经明确了
// 声明时未调用,因此会被认为是不被执行的代码,进行预解析
function foo() {
console.log('foo')
}
// 声明时未调用,因此会被认为是不被执行的代码,进行预解析
function fn() {}
// 函数立即执行,只进行一次全量解析
(function bar() {
})()
// 执行 foo,那么需要重新对 foo 函数进行全量解析,此时 foo 函数被解析了两次
foo();
如果在函数 foo 里面再次声明一个函数,foo 内部的函数也会被跟着解析两次(如果foo内部执行该函数)。嵌套层级太深甚至会导致更多次数的解析。因此,减少不必要的嵌套函数,能提高代码的执行效率。
注意:V8 引擎会对 parser 阶段的解析结果,缓存 3 天,不怎么变动的代码打包在一起,如公共代码,把经常变动的业务代码等打包到另外的 js 文件中,能够有效的提高执行效率。
Ignition
Ignition 是 v8 提供的一个解释器。作用是负责将抽象语法树 AST 转换为字节码「bytecode」。并且同时收集下一个阶段「编译」所需要的信息。这个过程,也可以理解为预编译过程。基于性能的考虑,预编译过程与编译过程有的时候不会区分的那么明显,有的代码在预编译阶段就能直接执行
TurboFan
TurboFan 是 v8 引擎的编译器模块。它会利用 Ignition 收集到的信息,将字节码转换为汇编代码,这也就是代码被最终执行的阶段
优化
提高代码执行效率,不要总是改变对象类型。
function foo(obj) {
return obj.name
}
obj0 = {
name: 'Alex'
}
obj1 = {
name: 'tom',
age: 1
}
obj2 = {
name: 'Jake',
age: 1,
gender: 1
}
由于JavaScript的动态性,并不能确定obj的类型,对于编译器而言obj1,obj2,obj3是三种不同的类型,TurboFan 无法针对优化,只能 De-optimize 操作。这意味着执行效率的降低
因此,定义函数时,严格要求参数格式保持一致,在实践中是非常重要的优化策略,这也是 typescript 的作用之一。
Orinoco
执行的 JavaScript 代码中,有大量的垃圾内存需要处理。甚至绝大多数内存占用都是垃圾。因此我们必须有一个机制来管理这些垃圾内存,用于回收利用。这就是垃圾回收器 Orinoco。
垃圾回收器会定期的执行以下任务
- 标记活动对象,和非活动对象「标记阶段」
- 回收被非活动对象占用的内存空间「清除阶段」
- 合并或者整理内存「整理阶段」
总结
v8 的 Compiler Pipeline 并非一开始就是使用的 Ignition + TurboFan 组合。也是在不断的迭代过程中演变而来。例如在他们之前,是 Full-codegen + Crankshaft,并且他们也共存过一段时间。
在官方文档中,提供了一个 PPT,我们可以观察不同版本的演变过程。该 PPT 介绍了为何要使用新的编译组合。
- 减少了内存占用
- 减少了启动时间
- 降低了复杂度